![]()
[Jun 21, 2026] Verified ACD-301 dumps and 47 unique questions
ACD-301 Dumps for Pass Guaranteed - Pass ACD-301 Exam 2026
NEW QUESTION # 10
You need to export data using an out-of-the-box Appian smart service. Which two formats are available (or data generation?
- A. CSV
- B. Excel
- C. JSDN
- D. XML
Answer: A,B
Explanation:
The two formats that are available for data generation using an out-of-the-box Appian smart service are:
A . CSV. This is a comma-separated values format that can be used to export data in a tabular form, such as records, reports, or grids. CSV files can be easily opened and manipulated by spreadsheet applications such as Excel or Google Sheets.
C . Excel. This is a format that can be used to export data in a spreadsheet form, with multiple worksheets, formatting, formulas, charts, and other features. Excel files can be opened by Excel or other compatible applications.
The other options are incorrect for the following reasons:
B . XML. This is a format that can be used to export data in a hierarchical form, using tags and attributes to define the structure and content of the data. XML files can be opened by text editors or XML parsers, but they are not supported by the out-of-the-box Appian smart service for data generation.
D . JSON. This is a format that can be used to export data in a structured form, using objects and arrays to represent the data. JSON files can be opened by text editors or JSON parsers, but they are not supported by the out-of-the-box Appian smart service for data generation. Verified Appian Documentation, section "Write to Data Store Entity" and "Write to Multiple Data Store Entities".
NEW QUESTION # 11
You are selling up a new cloud environment. The customer already has a system of record for Its employees and doesn't want to re-create them in Appian. so you are going to Implement LDAP authentication.
What are the next steps to configure LDAP authentication?
To answer, move the appropriate steps from the Option list to the Answer List area, and arrange them in the correct order. You may or may not use all the steps.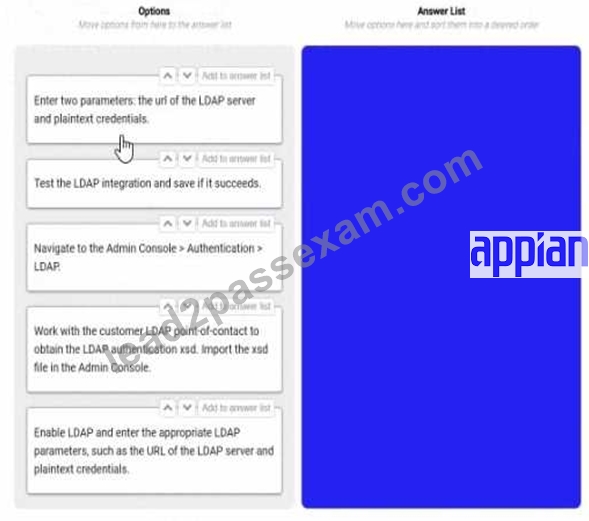
Answer:
Explanation: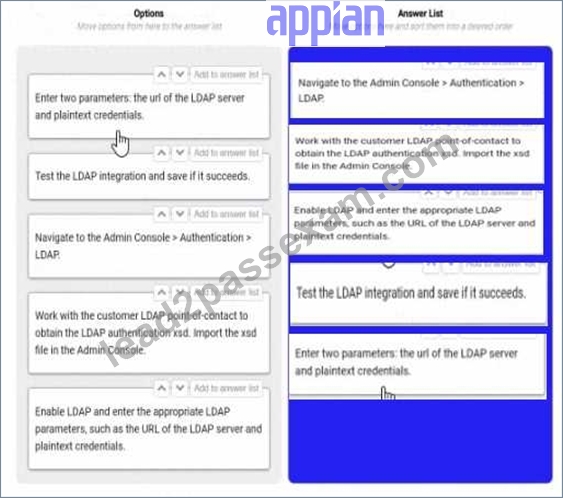
NEW QUESTION # 12
You are the project lead for an Appian project with a supportive product owner and complex business requirements involving a customer management system. Each week, you notice the product owner becoming more irritated and not devoting as much time to the project, resulting in tickets becoming delayed due to a lack of involvement. Which two types of meetings should you schedule to address this issue?
- A. An additional daily stand-up meeting to ensure you have more of the product owner's time.
- B. A sprint retrospective with the product owner and development team to discuss team performance.
- C. A risk management meeting with your program manager to escalate the delayed tickets.
- D. A meeting with the sponsor to discuss the product owner's performance and request a replacement.
Answer: B,C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing stakeholder engagement and ensuring smooth project progress are critical responsibilities. The scenario describes a product owner whose decreasing involvement is causing delays, which requires a proactive and collaborative approach rather than an immediate escalation to replacement. Let's analyze each option:
A . An additional daily stand-up meeting: While daily stand-ups are a core Agile practice to align the team, adding another one specifically to secure the product owner's time is inefficient. Appian's Agile methodology (aligned with Scrum) emphasizes that stand-ups are for the development team to coordinate, not to force stakeholder availability. The product owner's irritation might increase with additional meetings, making this less effective.
B . A risk management meeting with your program manager: This is a correct choice. Appian Lead Developer documentation highlights the importance of risk management in complex projects (e.g., customer management systems). Delays due to lack of product owner involvement constitute a project risk. Escalating this to the program manager ensures visibility and allows for strategic mitigation, such as resource reallocation or additional support, without directly confronting the product owner in a way that could damage the relationship. This aligns with Appian's project governance best practices.
C . A sprint retrospective with the product owner and development team: This is also a correct choice. The sprint retrospective, as per Appian's Agile guidelines, is a key ceremony to reflect on what's working and what isn't. Including the product owner fosters collaboration and provides a safe space to address their reduced involvement and its impact on ticket delays. It encourages team accountability and aligns with Appian's focus on continuous improvement in Agile development.
D . A meeting with the sponsor to discuss the product owner's performance and request a replacement: This is premature and not recommended as a first step. Appian's Lead Developer training emphasizes maintaining strong stakeholder relationships and resolving issues collaboratively before escalating to drastic measures like replacement. This option risks alienating the product owner and disrupting the project further, which contradicts Appian's stakeholder management principles.
Conclusion: The best approach combines B (risk management meeting) to address the immediate risk of delays with a higher-level escalation and C (sprint retrospective) to collaboratively resolve the product owner's engagement issues. These align with Appian's Agile and leadership strategies for Lead Developers.
Appian Lead Developer Certification: Agile Project Management Module (Risk Management and Stakeholder Engagement).
Appian Documentation: "Best Practices for Agile Development in Appian" (Sprint Retrospectives and Team Collaboration).
NEW QUESTION # 13
Your team has deployed an application to Production with an underperforming view. Unexpectedly, the production data is ten times that of what was tested, and you must remediate the issue. What is the best option you can take to mitigate their performance concerns?
- A. Create a materialized view or table.
- B. Bypass Appian's query rule by calling the database directly with a SQL statement.
- C. Introduce a data management policy to reduce the volume of data.
- D. Create a table which is loaded every hour with the latest data.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, addressing performance issues in production requires balancing Appian's best practices, scalability, and maintainability. The scenario involves an underperforming view due to a significant increase in data volume (ten times the tested amount), necessitating a solution that optimizes performance while adhering to Appian's architecture. Let's evaluate each option:
A . Bypass Appian's query rule by calling the database directly with a SQL statement:
This approach involves circumventing Appian's query rules (e.g., a!queryEntity) and directly executing SQL against the database. While this might offer a quick performance boost by avoiding Appian's abstraction layer, it violates Appian's core design principles. Appian Lead Developer documentation explicitly discourages direct database calls, as they bypass security (e.g., Appian's row-level security), auditing, and portability features. This introduces maintenance risks, dependencies on database-specific logic, and potential production instability-making it an unsustainable and non-recommended solution.
B . Create a table which is loaded every hour with the latest data:
This suggests implementing a staging table updated hourly (e.g., via an Appian process model or ETL process). While this could reduce query load by pre-aggregating data, it introduces latency (data is only fresh hourly), which may not meet real-time requirements typical in Appian applications (e.g., a customer-facing view). Additionally, maintaining an hourly refresh process adds complexity and overhead (e.g., scheduling, monitoring). Appian's documentation favors more efficient, real-time solutions over periodic refreshes unless explicitly required, making this less optimal for immediate performance remediation.
C . Create a materialized view or table:
This is the best choice. A materialized view (or table, depending on the database) pre-computes and stores query results, significantly improving retrieval performance for large datasets. In Appian, you can integrate a materialized view with a Data Store Entity, allowing a!queryEntity to fetch data efficiently without changing application logic. Appian Lead Developer training emphasizes leveraging database optimizations like materialized views to handle large data volumes, as they reduce query execution time while keeping data consistent with the source (via periodic or triggered refreshes, depending on the database). This aligns with Appian's performance optimization guidelines and addresses the tenfold data increase effectively.
D . Introduce a data management policy to reduce the volume of data:
This involves archiving or purging data to shrink the dataset (e.g., moving old records to an archive table). While a long-term data management policy is a good practice (and supported by Appian's Data Fabric principles), it doesn't immediately remediate the performance issue. Reducing data volume requires business approval, policy design, and implementation-delaying resolution. Appian documentation recommends combining such strategies with technical fixes (like C), but as a standalone solution, it's insufficient for urgent production concerns.
Conclusion: Creating a materialized view or table (C) is the best option. It directly mitigates performance by optimizing data retrieval, integrates seamlessly with Appian's Data Store, and scales for large datasets-all while adhering to Appian's recommended practices. The view can be refreshed as needed (e.g., via database triggers or schedules), balancing performance and data freshness. This approach requires collaboration with a DBA to implement but ensures a robust, Appian-supported solution.
Appian Documentation: "Performance Best Practices" (Optimizing Data Queries with Materialized Views).
Appian Lead Developer Certification: Application Performance Module (Database Optimization Techniques).
Appian Best Practices: "Working with Large Data Volumes in Appian" (Data Store and Query Performance).
NEW QUESTION # 14
You are planning a strategy around data volume testing for an Appian application that queries and writes to a MySQL database. You have administrator access to the Appian application and to the database. What are two key considerations when designing a data volume testing strategy?
- A. The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation.
- B. Testing with the correct amount of data should be in the definition of done as part of each sprint.
- C. Data model changes must wait until towards the end of the project.
- D. Data from previous tests needs to remain in the testing environment prior to loading prepopulated data.
- E. Large datasets must be loaded via Appian processes.
Answer: A,B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Data volume testing ensures an Appian application performs efficiently under realistic data loads, especially when interacting with external databases like MySQL. As an Appian Lead Developer with administrative access, the focus is on scalability, performance, and iterative validation. The two key considerations are:
Option C (The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation):
Determining the appropriate data volume is critical to simulate real-world usage. Appian's Performance Testing Best Practices recommend collaborating with stakeholders (e.g., project sponsors, business analysts) to define expected data sizes based on production scenarios. This ensures the test reflects actual requirements-like peak transaction volumes or record counts-rather than arbitrary guesses. For example, if the application will handle 1 million records in production, stakeholders must specify this to guide test data preparation.
Option D (Testing with the correct amount of data should be in the definition of done as part of each sprint):
Appian's Agile Development Guide emphasizes incorporating performance testing (including data volume) into the Definition of Done (DoD) for each sprint. This ensures that features are validated under realistic conditions iteratively, preventing late-stage performance issues. With admin access, you can query/write to MySQL and assess query performance or write latency with the specified data volume, aligning with Appian's recommendation to "test early and often." Option A (Data from previous tests needs to remain in the testing environment prior to loading prepopulated data): This is impractical and risky. Retaining old test data can skew results, introduce inconsistencies, or violate data integrity (e.g., duplicate keys in MySQL). Best practices advocate for a clean, controlled environment with fresh, prepopulated data per test cycle.
Option B (Large datasets must be loaded via Appian processes): While Appian processes can load data, this is not a requirement. With database admin access, you can use SQL scripts or tools like MySQL Workbench for faster, more efficient data population, bypassing Appian process overhead. Appian documentation notes this as a preferred method for large datasets.
Option E (Data model changes must wait until towards the end of the project): Delaying data model changes contradicts Agile principles and Appian's iterative design approach. Changes should occur as needed throughout development to adapt to testing insights, not be deferred.
NEW QUESTION # 15
For each requirement, match the most appropriate approach to creating or utilizing plug-ins Each approach will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.
Answer:
Explanation: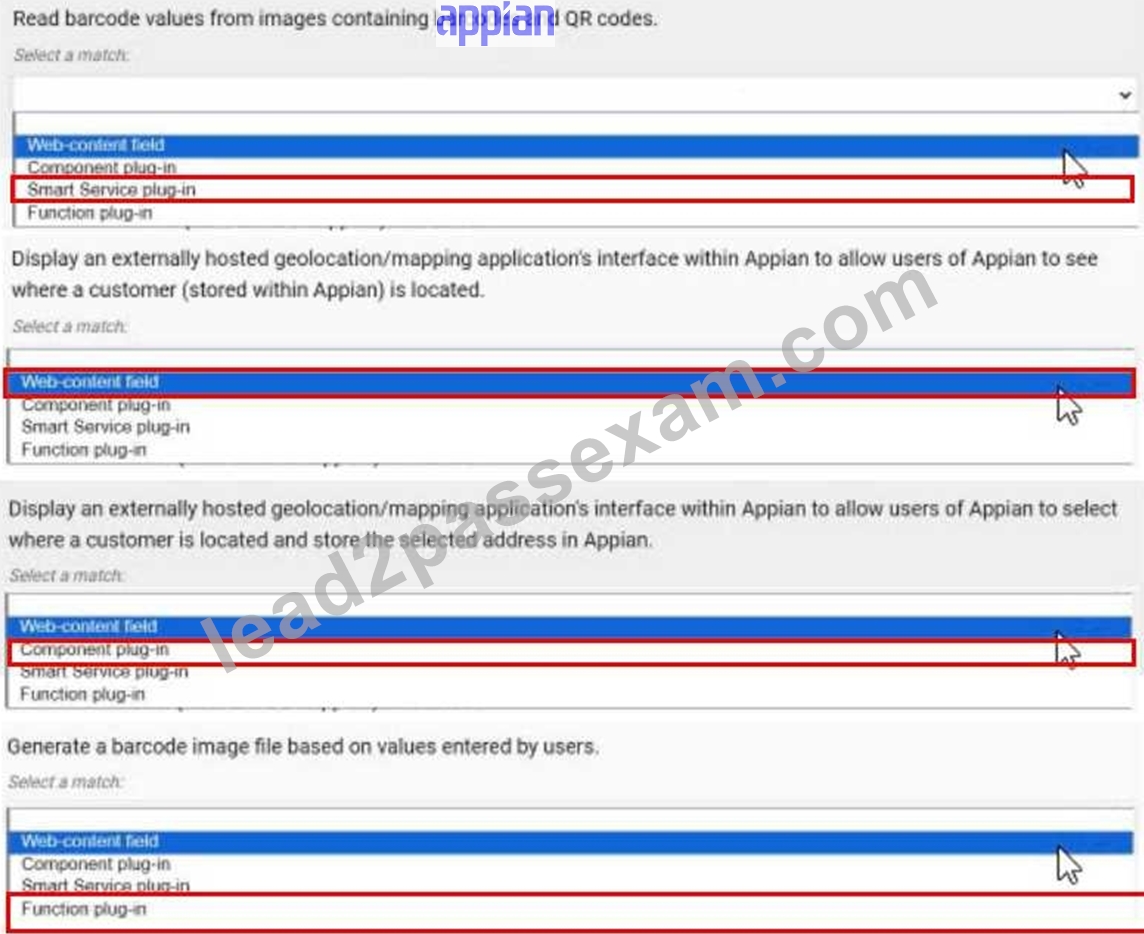
NEW QUESTION # 16
A customer wants to integrate a CSV file once a day into their Appian application, sent every night at 1:00 AM. The file contains hundreds of thousands of items to be used daily by users as soon as their workday starts at 8:00 AM. Considering the high volume of data to manipulate and the nature of the operation, what is the best technical option to process the requirement?
- A. Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements.
- B. Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures.
- C. Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration.
- D. Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data.
Answer: C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, handling a daily CSV integration with hundreds of thousands of items requires a solution that balances performance, scalability, and Appian's architectural strengths. The timing (1:00 AM integration, 8:00 AM availability) and data volume necessitate efficient processing and minimal runtime overhead. Let's evaluate each option based on Appian's official documentation and best practices:
A . Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements:
This approach involves parsing the CSV in a process model and using a looping mechanism (e.g., a subprocess or script task with fn!forEach) to process each item. While Appian process models are excellent for orchestrating workflows, they are not optimized for high-volume data processing. Looping over hundreds of thousands of records would strain the process engine, leading to timeouts, memory issues, or slow execution-potentially missing the 8:00 AM deadline. Appian's documentation warns against using process models for bulk data operations, recommending database-level processing instead. This is not a viable solution.
B . Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data:
This suggests loading the CSV into a table and creating an optimized database view (e.g., with indices and joins) for user queries via a!queryEntity. While this improves read performance for users at 8:00 AM, it doesn't address the integration process itself. The question focuses on processing the CSV ("manipulate" and "operation"), not just querying. Building a view assumes the data is already loaded and transformed, leaving the heavy lifting of integration unaddressed. This option is incomplete and misaligned with the requirement's focus on processing efficiency.
C . Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration:
This is the best choice. Stored procedures, executed in the database, are designed for high-volume data manipulation (e.g., parsing CSV, transforming data, and applying business logic). In this scenario, you can configure an Appian process model to trigger at 1:00 AM (using a timer event) after the CSV is received (e.g., via FTP or Appian's File System utilities), then call a stored procedure via the "Execute Stored Procedure" smart service. The stored procedure can efficiently bulk-load the CSV (e.g., using SQL's BULK INSERT or equivalent), process the data, and update tables-all within the database's optimized environment. This ensures completion by 8:00 AM and aligns with Appian's recommendation to offload complex, large-scale data operations to the database layer, maintaining Appian as the orchestration layer.
D . Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures:
This hybrid approach splits the workload: simple tasks (e.g., validation) in a process model, and complex tasks (e.g., transformations) in stored procedures. While this leverages Appian's strengths (orchestration) and database efficiency, it adds unnecessary complexity. Managing two layers of processing increases maintenance overhead and risks partial failures (e.g., process model timeouts before stored procedures run). Appian's best practices favor a single, cohesive approach for bulk data integration, making this less efficient than a pure stored procedure solution (C).
Conclusion: Creating a set of stored procedures (C) is the best option. It leverages the database's native capabilities to handle the high volume and complexity of the CSV integration, ensuring fast, reliable processing between 1:00 AM and 8:00 AM. Appian orchestrates the trigger and integration (e.g., via a process model), while the stored procedure performs the heavy lifting-aligning with Appian's performance guidelines for large-scale data operations.
Appian Documentation: "Execute Stored Procedure Smart Service" (Process Modeling > Smart Services).
Appian Lead Developer Certification: Data Integration Module (Handling Large Data Volumes).
Appian Best Practices: "Performance Considerations for Data Integration" (Database vs. Process Model Processing).
NEW QUESTION # 17
What are two advantages of having High Availability (HA) for Appian Cloud applications?
- A. Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure.
- B. An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions.
- C. A typical Appian Cloud HA instance is composed of two active nodes.
- D. In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data.
Answer: A,D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
High Availability (HA) in Appian Cloud is designed to ensure that applications remain operational and data integrity is maintained even in the face of hardware failures, network issues, or other disruptions. Appian's Cloud Architecture and HA documentation outline the benefits, focusing on redundancy, minimal downtime, and data protection. The question asks for two advantages, and the options must align with these core principles.
Option B (Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure):
This is a key advantage of HA. Appian Cloud HA instances use multiple active nodes to replicate data and transactions in real-time across the cluster. This redundancy ensures that if one node fails, others can take over without data loss, eliminating single points of failure. This is a fundamental feature of Appian's HA setup, leveraging distributed architecture to enhance reliability, as detailed in the Appian Cloud High Availability Guide.
Option D (In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data):
This is another significant advantage. Appian Cloud HA is engineered to provide rapid recovery and minimal data loss. The Service Level Agreement (SLA) and HA documentation specify that in the case of a failure, the system failover is designed to complete within a short timeframe (typically under 15 minutes), with data loss limited to the last minute due to synchronous replication. This ensures business continuity and meets stringent uptime and data integrity requirements.
Option A (An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions):
This is a description of the HA architecture rather than an advantage. While running nodes across different availability zones and regions enhances fault tolerance, the benefit is the resulting redundancy and availability, which are captured in Options B and D. This option is more about implementation than a direct user or operational advantage.
Option C (A typical Appian Cloud HA instance is composed of two active nodes):
This is a factual statement about the architecture but not an advantage. The number of nodes (typically two or more, depending on configuration) is a design detail, not a benefit. The advantage lies in what this setup enables (e.g., redundancy and quick recovery), as covered by B and D.
The two advantages-continuous replication for redundancy (B) and fast recovery with minimal data loss (D)-reflect the primary value propositions of Appian Cloud HA, ensuring both operational resilience and data integrity for users.
The two advantages of having High Availability (HA) for Appian Cloud applications are:
B . Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure. This is an advantage of having HA, as it ensures that there is always a backup copy of data and transactions in case one of the nodes fails or becomes unavailable. This also improves data integrity and consistency across the nodes, as any changes made to one node are automatically propagated to the other node.
D). In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data. This is an advantage of having HA, as it guarantees a high level of service availability and reliability for your Appian instance. If one of the nodes fails or becomes unavailable, the other node will take over and continue to serve requests without any noticeable downtime or data loss for your users.
NEW QUESTION # 18
You are designing a process that is anticipated to be executed multiple times a day. This process retrieves data from an external system and then calls various utility processes as needed. The main process will not use the results of the utility processes, and there are no user forms anywhere.
Which design choice should be used to start the utility processes and minimize the load on the execution engines?
- A. Use the Start Process Smart Service to start the utility processes.
- B. Start the utility processes via a subprocess asynchronously.
- C. Start the utility processes via a subprocess synchronously.
- D. Use Process Messaging to start the utility process.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a process that executes frequently (multiple times a day) and calls utility processes without using their results requires optimizing performance and minimizing load on Appian's execution engines. The absence of user forms indicates a backend process, so user experience isn't a concern-only engine efficiency matters. Let's evaluate each option:
A . Use the Start Process Smart Service to start the utility processes:
The Start Process Smart Service launches a new process instance independently, creating a separate process in the Work Queue. While functional, it increases engine load because each utility process runs as a distinct instance, consuming engine resources and potentially clogging the Java Work Queue, especially with frequent executions. Appian's performance guidelines discourage unnecessary separate process instances for utility tasks, favoring integrated subprocesses, making this less optimal.
B . Start the utility processes via a subprocess synchronously:
Synchronous subprocesses (e.g., a!startProcess with isAsync: false) execute within the main process flow, blocking until completion. For utility processes not used by the main process, this creates unnecessary delays, increasing execution time and engine load. With frequent daily executions, synchronous subprocesses could strain engines, especially if utility processes are slow or numerous. Appian's documentation recommends asynchronous execution for non-dependent, non-blocking tasks, ruling this out.
C . Use Process Messaging to start the utility process:
Process Messaging (e.g., sendMessage() in Appian) is used for inter-process communication, not for starting processes. It's designed to pass data between running processes, not initiate new ones. Attempting to use it for starting utility processes would require additional setup (e.g., a listening process) and isn't a standard or efficient method. Appian's messaging features are for coordination, not process initiation, making this inappropriate.
D . Start the utility processes via a subprocess asynchronously:
This is the best choice. Asynchronous subprocesses (e.g., a!startProcess with isAsync: true) execute independently of the main process, offloading work to the engine without blocking or delaying the parent process. Since the main process doesn't use the utility process results and there are no user forms, asynchronous execution minimizes engine load by distributing tasks across time, reducing Work Queue pressure during frequent executions. Appian's performance best practices recommend asynchronous subprocesses for non-dependent, utility tasks to optimize engine utilization, making this ideal for minimizing load.
Conclusion: Starting the utility processes via a subprocess asynchronously (D) minimizes engine load by allowing independent execution without blocking the main process, aligning with Appian's performance optimization strategies for frequent, backend processes.
Appian Documentation: "Process Model Performance" (Synchronous vs. Asynchronous Subprocesses).
Appian Lead Developer Certification: Process Design Module (Optimizing Engine Load).
Appian Best Practices: "Designing Efficient Utility Processes" (Asynchronous Execution).
NEW QUESTION # 19
The business database for a large, complex Appian application is to undergo a migration between database technologies, as well as interface and process changes. The project manager asks you to recommend a test strategy. Given the changes, which two items should be included in the test strategy?
- A. Tests that ensure users can still successfully log into the platform
- B. Penetration testing of the Appian platform
- C. A regression test of all existing system functionality
- D. Internationalization testing of the Appian platform
- E. Tests for each of the interfaces and process changes
Answer: C,E
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, recommending a test strategy for a large, complex application undergoing a database migration (e.g., from Oracle to PostgreSQL) and interface/process changes requires focusing on ensuring system stability, functionality, and the specific updates. The strategy must address risks tied to the scope-database technology shift, interface modifications, and process updates-while aligning with Appian's testing best practices. Let's evaluate each option:
A . Internationalization testing of the Appian platform:
Internationalization testing verifies that the application supports multiple languages, locales, and formats (e.g., date formats). While valuable for global applications, the scenario doesn't indicate a change in localization requirements tied to the database migration, interfaces, or processes. Appian's platform handles internationalization natively (e.g., via locale settings), and this isn't impacted by database technology or UI/process changes unless explicitly stated. This is out of scope for the given context and not a priority.
B . A regression test of all existing system functionality:
This is a critical inclusion. A database migration between technologies can affect data integrity, queries (e.g., a!queryEntity), and performance due to differences in SQL dialects, indexing, or drivers. Regression testing ensures that all existing functionality-records, reports, processes, and integrations-works as expected post-migration. Appian Lead Developer documentation mandates regression testing for significant infrastructure changes like this, as unmapped edge cases (e.g., datatype mismatches) could break the application. Given the "large, complex" nature, full-system validation is essential to catch unintended impacts.
C . Penetration testing of the Appian platform:
Penetration testing assesses security vulnerabilities (e.g., injection attacks). While security is important, the changes described-database migration, interface, and process updates-don't inherently alter Appian's security model (e.g., authentication, encryption), which is managed at the platform level. Appian's cloud or on-premise security isn't directly tied to database technology unless new vulnerabilities are introduced (not indicated here). This is a periodic concern, not specific to this migration, making it less relevant than functional validation.
D . Tests for each of the interfaces and process changes:
This is also essential. The project includes explicit "interface and process changes" alongside the migration. Interface updates (e.g., SAIL forms) might rely on new data structures or queries, while process changes (e.g., modified process models) could involve updated nodes or logic. Testing each change ensures these components function correctly with the new database and meet business requirements. Appian's testing guidelines emphasize targeted validation of modified components to confirm they integrate with the migrated data layer, making this a primary focus of the strategy.
E . Tests that ensure users can still successfully log into the platform:
Login testing verifies authentication (e.g., SSO, LDAP), typically managed by Appian's security layer, not the business database. A database migration affects application data, not user authentication, unless the database stores user credentials (uncommon in Appian, which uses separate identity management). While a quick sanity check, it's narrow and subsumed by broader regression testing (B), making it redundant as a standalone item.
Conclusion: The two key items are B (regression test of all existing system functionality) and D (tests for each of the interfaces and process changes). Regression testing (B) ensures the database migration doesn't disrupt the entire application, while targeted testing (D) validates the specific interface and process updates. Together, they cover the full scope-existing stability and new functionality-aligning with Appian's recommended approach for complex migrations and modifications.
Appian Documentation: "Testing Best Practices" (Regression and Component Testing).
Appian Lead Developer Certification: Application Maintenance Module (Database Migration Strategies).
Appian Best Practices: "Managing Large-Scale Changes in Appian" (Test Planning).
NEW QUESTION # 20
Your application contains a process model that is scheduled to run daily at a certain time, which kicks off a user input task to a specified user on the 1st time zone for morning data collection. The time zone is set to the (default) pm!timezone. In this situation, what does the pm!timezone reflect?
- A. The time zone of the user who most recently published the process model.
- B. The time zone of the server where Appian is installed.
- C. The time zone of the user who is completing the input task.
- D. The default time zone for the environment as specified in the Administration Console.
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
In Appian, the pm!timezone variable is a process variable automatically available in process models, reflecting the time zone context for scheduled or time-based operations. Understanding its behavior is critical for scheduling tasks accurately, especially in scenarios like this where a process runs daily and assigns a user input task.
Option C (The default time zone for the environment as specified in the Administration Console):
This is the correct answer. Per Appian's Process Model documentation, when a process model uses pm!timezone and no custom time zone is explicitly set, it defaults to the environment's time zone configured in the Administration Console (under System > Time Zone settings). For scheduled processes, such as one running "daily at a certain time," Appian uses this default time zone to determine when the process triggers. In this case, the task assignment occurs based on the schedule, and pm!timezone reflects the environment's setting, not the user's location.
Option A (The time zone of the server where Appian is installed): This is incorrect. While the server's time zone might influence underlying system operations, Appian abstracts this through the Administration Console's time zone setting. The pm!timezone variable aligns with the configured environment time zone, not the raw server setting.
Option B (The time zone of the user who most recently published the process model): This is irrelevant. Publishing a process model does not tie pm!timezone to the publisher's time zone. Appian's scheduling is system-driven, not user-driven in this context.
Option D (The time zone of the user who is completing the input task): This is also incorrect. While Appian can adjust task display times in the user interface to the assigned user's time zone (based on their profile settings), the pm!timezone in the process model reflects the environment's default time zone for scheduling purposes, not the assignee's.
For example, if the Administration Console is set to EST (Eastern Standard Time), the process will trigger daily at the specified time in EST, regardless of the assigned user's location. The "1st time zone" phrasing in the question appears to be a typo or miscommunication, but it doesn't change the fact that pm!timezone defaults to the environment setting.
NEW QUESTION # 21
You are required to configure a connection so that Jira can inform Appian when specific tickets change (using a webhook). Which three required steps will allow you to connect both systems?
- A. Create a Web API object and set up the correct security.
- B. Create a new API Key and associate a service account.
- C. Create an integration object from Appian to Jira to periodically check the ticket status.
- D. Give the service account system administrator privileges.
- E. Configure the connection in Jira specifying the URL and credentials.
Answer: A,B,E
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Configuring a webhook connection from Jira to Appian requires setting up a mechanism for Jira to push ticket change notifications to Appian in real-time. This involves creating an endpoint in Appian to receive the webhook and configuring Jira to send the data. Appian's Integration Best Practices and Web API documentation provide the framework for this process.
Option A (Create a Web API object and set up the correct security):
This is a required step. In Appian, a Web API object serves as the endpoint to receive incoming webhook requests from Jira. You must define the API structure (e.g., HTTP method, input parameters) and configure security (e.g., basic authentication, API key, or OAuth) to validate incoming requests. Appian recommends using a service account with appropriate permissions to ensure secure access, aligning with the need for a controlled webhook receiver.
Option B (Configure the connection in Jira specifying the URL and credentials):
This is essential. In Jira, you need to set up a webhook by providing the Appian Web API's URL (e.g., https://<appian-site>/suite/webapi/<web-api-name>) and the credentials or authentication method (e.g., API key or basic auth) that match the security setup in Appian. This ensures Jira can successfully send ticket change events to Appian.
Option C (Create a new API Key and associate a service account):
This is necessary for secure authentication. Appian recommends using an API key tied to a service account for webhook integrations. The service account should have permissions to process the incoming data (e.g., write to a process or data store) but not excessive privileges. This step complements the Web API security setup and Jira configuration.
Option D (Give the service account system administrator privileges):
This is unnecessary and insecure. System administrator privileges grant broad access, which is overkill for a webhook integration. Appian's security best practices advocate for least-privilege principles, limiting the service account to the specific objects or actions needed (e.g., executing the Web API).
Option E (Create an integration object from Appian to Jira to periodically check the ticket status):
This is incorrect for a webhook scenario. Webhooks are push-based, where Jira notifies Appian of changes. Creating an integration object for periodic polling (pull-based) is a different approach and not required for the stated requirement of Jira informing Appian via webhook.
These three steps (A, B, C) establish a secure, functional webhook connection without introducing unnecessary complexity or security risks.
The three required steps that will allow you to connect both systems are:
A . Create a Web API object and set up the correct security. This will allow you to define an endpoint in Appian that can receive requests from Jira via webhook. You will also need to configure the security settings for the Web API object, such as authentication method, allowed origins, and access control.
B . Configure the connection in Jira specifying the URL and credentials. This will allow you to set up a webhook in Jira that can send requests to Appian when specific tickets change. You will need to specify the URL of the Web API object in Appian, as well as any credentials required for authentication.
C . Create a new API Key and associate a service account. This will allow you to generate a unique token that can be used for authentication between Jira and Appian. You will also need to create a service account in Appian that has permissions to access or update data related to Jira tickets.
The other options are incorrect for the following reasons:
D . Give the service account system administrator privileges. This is not required and could pose a security risk, as giving system administrator privileges to a service account could allow it to perform actions that are not related to Jira tickets, such as modifying system settings or accessing sensitive data.
E . Create an integration object from Appian to Jira to periodically check the ticket status. This is not required and could cause unnecessary overhead, as creating an integration object from Appian to Jira would involve polling Jira for ticket status changes, which could consume more resources than using webhook notifications. Verified Appian Documentation, section "Web API" and "API Keys".
NEW QUESTION # 22
You need to design a complex Appian integration to call a RESTful API. The RESTful API will be used to update a case in a customer's legacy system.
What are three prerequisites for designing the integration?
- A. Understand the content of the expected body, including each field type and their limits.
- B. Define the HTTP method that the integration will use.
- C. Understand the business rules to be applied to ensure the business logic of the data.
- D. Understand whether this integration will be used in an interface or in a process model.
- E. Understand the different error codes managed by the API and the process of error handling in Appian.
Answer: A,B,E
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a complex integration to a RESTful API for updating a case in a legacy system requires a structured approach to ensure reliability, performance, and alignment with business needs. The integration involves sending a JSON payload (implied by the context) and handling responses, so the focus is on technical and functional prerequisites. Let's evaluate each option:
A . Define the HTTP method that the integration will use:
This is a primary prerequisite. RESTful APIs use HTTP methods (e.g., POST, PUT, GET) to define the operation-here, updating a case likely requires PUT or POST. Appian's Connected System and Integration objects require specifying the method to configure the HTTP request correctly. Understanding the API's method ensures the integration aligns with its design, making this essential for design. Appian's documentation emphasizes choosing the correct HTTP method as a foundational step.
B . Understand the content of the expected body, including each field type and their limits:
This is also critical. The JSON payload for updating a case includes fields (e.g., text, dates, numbers), and the API expects a specific structure with field types (e.g., string, integer) and limits (e.g., max length, size constraints). In Appian, the Integration object requires a dictionary or CDT to construct the body, and mismatches (e.g., wrong types, exceeding limits) cause errors (e.g., 400 Bad Request). Appian's best practices mandate understanding the API schema to ensure data compatibility, making this a key prerequisite.
C . Understand whether this integration will be used in an interface or in a process model:
While knowing the context (interface vs. process model) is useful for design (e.g., synchronous vs. asynchronous calls), it's not a prerequisite for the integration itself-it's a usage consideration. Appian supports integrations in both contexts, and the integration's design (e.g., HTTP method, body) remains the same. This is secondary to technical API details, so it's not among the top three prerequisites.
D . Understand the different error codes managed by the API and the process of error handling in Appian:
This is essential. RESTful APIs return HTTP status codes (e.g., 200 OK, 400 Bad Request, 500 Internal Server Error), and the customer's API likely documents these for failure scenarios (e.g., invalid data, server issues). Appian's Integration objects can handle errors via error mappings or process models, and understanding these codes ensures robust error handling (e.g., retry logic, user notifications). Appian's documentation stresses error handling as a core design element for reliable integrations, making this a primary prerequisite.
E . Understand the business rules to be applied to ensure the business logic of the data:
While business rules (e.g., validating case data before sending) are important for the overall application, they aren't a prerequisite for designing the integration itself-they're part of the application logic (e.g., process model or interface). The integration focuses on technical interaction with the API, not business validation, which can be handled separately in Appian. This is a secondary concern, not a core design requirement for the integration.
Conclusion: The three prerequisites are A (define the HTTP method), B (understand the body content and limits), and D (understand error codes and handling). These ensure the integration is technically sound, compatible with the API, and resilient to errors-critical for a complex RESTful API integration in Appian.
Appian Documentation: "Designing REST Integrations" (HTTP Methods, Request Body, Error Handling).
Appian Lead Developer Certification: Integration Module (Prerequisites for Complex Integrations).
Appian Best Practices: "Building Reliable API Integrations" (Payload and Error Management).
To design a complex Appian integration to call a RESTful API, you need to have some prerequisites, such as:
Define the HTTP method that the integration will use. The HTTP method is the action that the integration will perform on the API, such as GET, POST, PUT, PATCH, or DELETE. The HTTP method determines how the data will be sent and received by the API, and what kind of response will be expected.
Understand the content of the expected body, including each field type and their limits. The body is the data that the integration will send to the API, or receive from the API, depending on the HTTP method. The body can be in different formats, such as JSON, XML, or form data. You need to understand how to structure the body according to the API specification, and what kind of data types and values are allowed for each field.
Understand the different error codes managed by the API and the process of error handling in Appian. The error codes are the status codes that indicate whether the API request was successful or not, and what kind of problem occurred if not. The error codes can range from 200 (OK) to 500 (Internal Server Error), and each code has a different meaning and implication. You need to understand how to handle different error codes in Appian, and how to display meaningful messages to the user or log them for debugging purposes.
The other two options are not prerequisites for designing the integration, but rather considerations for implementing it.
Understand whether this integration will be used in an interface or in a process model. This is not a prerequisite, but rather a decision that you need to make based on your application requirements and design. You can use an integration either in an interface or in a process model, depending on where you need to call the API and how you want to handle the response. For example, if you need to update a case in real-time based on user input, you may want to use an integration in an interface. If you need to update a case periodically based on a schedule or an event, you may want to use an integration in a process model.
Understand the business rules to be applied to ensure the business logic of the data. This is not a prerequisite, but rather a part of your application logic that you need to implement after designing the integration. You need to apply business rules to validate, transform, or enrich the data that you send or receive from the API, according to your business requirements and logic. For example, you may need to check if the case status is valid before updating it in the legacy system, or you may need to add some additional information to the case data before displaying it in Appian.
NEW QUESTION # 23
You are running an inspection as part of the first deployment process from TEST to PROD. You receive a notice that one of your objects will not deploy because it is dependent on an object from an application owned by a separate team.
What should be your next step?
- A. Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints.
- B. Halt the production deployment and contact the other team for guidance on promoting the object to PROD.
- C. Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk.
- D. Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing a deployment from TEST to PROD requires careful handling of dependencies, especially when objects from another team's application are involved. The scenario describes a dependency issue during deployment, signaling a need for collaboration and governance. Let's evaluate each option:
A . Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD:
This approach involves duplicating the object, which introduces redundancy, maintenance risks, and potential version control issues. It violates Appian's governance principles, as objects should be owned and managed by their respective teams to ensure consistency and avoid conflicts. Appian's deployment best practices discourage duplicating objects unless absolutely necessary, making this an unsustainable and risky solution.
B . Halt the production deployment and contact the other team for guidance on promoting the object to PROD:
This is the correct step. When an object from another application (owned by a separate team) is a dependency, Appian's deployment process requires coordination to ensure both applications' objects are deployed in sync. Halting the deployment prevents partial deployments that could break functionality, and contacting the other team aligns with Appian's collaboration and governance guidelines. The other team can provide the necessary object version, adjust their deployment timeline, or resolve the dependency, ensuring a stable PROD environment.
C . Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk:
This approach risks deploying an incomplete or unstable application if the dependency isn't fully resolved. Even with "few dependencies" and "low risk," deploying without the other team's object could lead to runtime errors or broken functionality in PROD. Appian's documentation emphasizes thorough dependency management during deployment, requiring all objects (including those from other applications) to be promoted together, making this risky and not recommended.
D . Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints:
Deploying without dependencies creates an incomplete solution, potentially leaving the application non-functional or unstable in PROD. Appian's deployment process ensures all dependencies are included to maintain application integrity, and partial deployments are discouraged unless explicitly planned (e.g., phased rollouts). This option delays resolution and increases risk, contradicting Appian's best practices for Production stability.
Conclusion: Halting the production deployment and contacting the other team for guidance (B) is the next step. It ensures proper collaboration, aligns with Appian's governance model, and prevents deployment errors, providing a safe and effective resolution.
Appian Documentation: "Deployment Best Practices" (Managing Dependencies Across Applications).
Appian Lead Developer Certification: Application Management Module (Cross-Team Collaboration).
Appian Best Practices: "Handling Production Deployments" (Dependency Resolution).
NEW QUESTION # 24
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage Review the specs for four environments in the following image.
Which environment should you use for load testing7
- A. acme
- B. acmetest
- C. acmeuat
- D. acmedev
Answer: C
Explanation:
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2 acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8 acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat):This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
Option B (acmedev):The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme):The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest):The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
NEW QUESTION # 25
You are just starting with a new team that has been working together on an application for months. They ask you to review some of their views that have been degrading in performance. The views are highly complex with hundreds of lines of SQL. What is the first step in troubleshooting the degradation?
- A. Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge.
- B. Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed.
- C. Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance.
- D. Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Troubleshooting performance degradation in complex SQL views within an Appian application requires a systematic approach. The views, described as having hundreds of lines of SQL, suggest potential issues with query execution, indexing, or join efficiency. As a new team member, the first step should focus on quickly identifying the root cause without overhauling the system prematurely. Appian's Performance Troubleshooting Guide and database optimization best practices provide the framework for this process.
Option B (Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge):
This is the recommended first step. Running an EXPLAIN statement (or equivalent, such as EXPLAIN PLAN in some databases) analyzes the query execution plan, revealing details like full table scans, missing indices, or inefficient joins. This technical analysis can identify immediate optimization opportunities (e.g., adding indices or rewriting subqueries) without requiring business input, allowing you to address low-hanging fruit quickly. Appian encourages using database tools to diagnose performance issues before involving stakeholders, making this a practical starting point as you familiarize yourself with the application.
Option A (Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance):
This is too broad and time-consuming as a first step. Understanding business needs and normalizing tables are valuable but require collaboration with the team and stakeholders, delaying action. It's better suited for a later phase after initial technical analysis.
Option C (Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed):
Manually checking indices is useful but inefficient without first knowing which queries are problematic. The EXPLAIN statement provides targeted insights into index usage, making it a more direct initial step than a manual table-by-table review.
Option D (Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure):
Identifying null values and planning restructures is a long-term optimization strategy, not a first step. It requires team input and may not address the immediate performance degradation, which is better tackled with query-level diagnostics.
Starting with an EXPLAIN statement allows you to gather data-driven insights, align with Appian's performance troubleshooting methodology, and proceed with informed optimizations.
NEW QUESTION # 26
You are on a call with a new client, and their program lead is concerned about how their legacy systems will integrate with Appian. The lead wants to know what authentication methods are supported by Appian. Which three authentication methods are supported?
- A. API Keys
- B. Biometrics
- C. CAC
- D. OAuth
- E. SAML
- F. Active Directory
Answer: D,E,F
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, addressing a client's concerns about integrating legacy systems with Appian requires accurately identifying supported authentication methods for system-to-system communication or user access. The question focuses on Appian's integration capabilities, likely for both user authentication (e.g., SSO) and API authentication, as legacy system integration often involves both. Appian's documentation outlines supported methods in its Connected Systems and security configurations. Let's evaluate each option:
A . API Keys:
API Key authentication involves a static key sent in requests (e.g., via headers). Appian supports this for outbound integrations in Connected Systems (e.g., HTTP Authentication with an API key), allowing legacy systems to authenticate Appian calls. However, it's not a user authentication method for Appian's platform login-it's for system-to-system integration. While supported, it's less common for legacy system SSO or enterprise use cases compared to other options, making it a lower-priority choice here.
B . Biometrics:
Biometrics (e.g., fingerprint, facial recognition) isn't natively supported by Appian for platform authentication or integration. Appian relies on standard enterprise methods (e.g., username/password, SSO), and biometric authentication would require external identity providers or custom clients, not Appian itself. Documentation confirms no direct biometric support, ruling this out as an Appian-supported method.
C . SAML:
Security Assertion Markup Language (SAML) is fully supported by Appian for user authentication via Single Sign-On (SSO). Appian integrates with SAML 2.0 identity providers (e.g., Okta, PingFederate), allowing users to log in using credentials from legacy systems that support SAML-based SSO. This is a key enterprise method, widely used for integrating with existing identity management systems, and explicitly listed in Appian's security configuration options-making it a top choice.
D . CAC:
Common Access Card (CAC) authentication, often used in government contexts with smart cards, isn't natively supported by Appian as a standalone method. While Appian can integrate with CAC via SAML or PKI (Public Key Infrastructure) through an identity provider, it's not a direct Appian authentication option. Documentation mentions smart card support indirectly via SSO configurations, but CAC itself isn't explicitly listed, making it less definitive than other methods.
E . OAuth:
OAuth (specifically OAuth 2.0) is supported by Appian for both outbound integrations (e.g., Authorization Code Grant, Client Credentials) and inbound API authentication (e.g., securing Appian Web APIs). For legacy system integration, Appian can use OAuth to authenticate with APIs (e.g., Google, Salesforce) or allow legacy systems to call Appian services securely. Appian's Connected System framework includes OAuth configuration, making it a versatile, standards-based method highly relevant to the client's needs.
F . Active Directory:
Active Directory (AD) integration via LDAP (Lightweight Directory Access Protocol) is supported for user authentication in Appian. It allows synchronization of users and groups from AD, enabling SSO or direct login with AD credentials. For legacy systems using AD as an identity store, this is a seamless integration method. Appian's documentation confirms LDAP/AD as a core authentication option, widely adopted in enterprise environments-making it a strong fit.
Conclusion: The three supported authentication methods are C (SAML), E (OAuth), and F (Active Directory). These align with Appian's enterprise-grade capabilities for legacy system integration: SAML for SSO, OAuth for API security, and AD for user management. API Keys (A) are supported but less prominent for user authentication, CAC (D) is indirect, and Biometrics (B) isn't supported natively. This selection reassures the client of Appian's flexibility with common legacy authentication standards.
Appian Documentation: "Authentication for Connected Systems" (OAuth, API Keys).
Appian Documentation: "Configuring Authentication" (SAML, LDAP/Active Directory).
Appian Lead Developer Certification: Integration Module (Authentication Methods).
NEW QUESTION # 27
For each scenario outlined, match the best tool to use to meet expectations. Each tool will be used once Note: To change your responses, you may deselected your response by clicking the blank space at the top of the selection list.
Answer:
Explanation: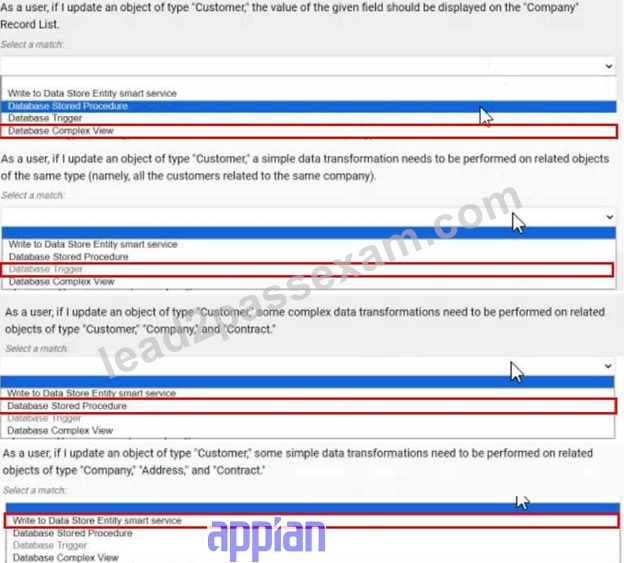
NEW QUESTION # 28
Your Agile Scrum project requires you to manage two teams, with three developers per team. Both teams are to work on the same application in parallel. How should the work be divided between the teams, avoiding issues caused by cross-dependency?
- A. Allocate stories to each team based on the cumulative years of experience of the team members.
- B. Have each team choose the stories they would like to work on based on personal preference.
- C. Group epics and stories by technical difficulty, and allocate one team the more challenging stories.
- D. Group epics and stories by feature, and allocate work between each team by feature.
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
In an Agile Scrum environment with two teams working on the same application in parallel, effective work division is critical to avoid cross-dependency, which can lead to delays, conflicts, and inefficiencies. Appian's Agile Development Best Practices emphasize team autonomy and minimizing dependencies to ensure smooth progress.
Option B (Group epics and stories by feature, and allocate work between each team by feature):
This is the recommended approach. By dividing the application's functionality into distinct features (e.g., Team 1 handles customer management, Team 2 handles campaign tracking), each team can work independently on a specific domain. This reduces cross-dependency because teams are not reliant on each other's deliverables within a sprint. Appian's guidance on multi-team projects suggests feature-based partitioning as a best practice, allowing teams to own their backlog items, design, and testing without frequent coordination. For example, Team 1 can develop and test customer-related interfaces while Team 2 works on campaign processes, merging their work during integration phases.
Option A (Group epics and stories by technical difficulty, and allocate one team the more challenging stories):
This creates an imbalance, potentially overloading one team and underutilizing the other, which can lead to morale issues and uneven progress. It also doesn't address cross-dependency, as challenging stories might still require input from both teams (e.g., shared data models), increasing coordination needs.
Option C (Allocate stories to each team based on the cumulative years of experience of the team members):
Experience-based allocation ignores the project's functional structure and can result in mismatched skills for specific features. It also risks dependencies if experienced team members are needed across teams, complicating parallel work.
Option D (Have each team choose the stories they would like to work on based on personal preference):
This lacks structure and could lead to overlap, duplication, or neglect of critical features. It increases the risk of cross-dependency as teams might select interdependent stories without coordination, undermining parallel development.
Feature-based division aligns with Scrum principles of self-organization and minimizes dependencies, making it the most effective strategy for this scenario.
NEW QUESTION # 29
......
Latest 100% Passing Guarantee - Brilliant ACD-301 Exam Questions PDF: https://www.lead2passexam.com/Appian/valid-ACD-301-exam-dumps.html
ACD-301 Exam Dumps - Try Best ACD-301 Exam Questions: https://drive.google.com/open?id=1zZRChOdtVr4RY6-MvN3vMB7LT9QDYnlR